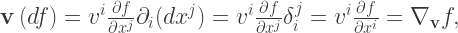There’s a way of motivating the notions of tangent vectors and covectors that’s hinted at but generally glossed over – at least in the physics courses that I take. This post is a quick overview, serving mostly as a reminder to myself of the topic. Please excuse the lack of rigour.
I will use the Einstein summation convention throughout,

and hopefully by the end I’ll even have explained why it makes sense.
Tangent vectors
We have an 

Let 

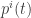




This motivates the study of all objects that transform this way, and they are called contravariant vectors, or contravectors, or just vectors.
Now, so far the vectors are just 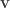


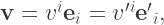
and for now these basis vectors
A vector lives at a single point 
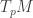
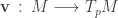

Differential operators
Let 


and note that we’re not really adding the vector 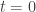
We might worry that this is coordinate system-dependent, so lets try to write the same quantity down in the primed coordinate system, using the transformation properties of
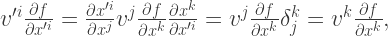
so our directional derivative is coordinate-invariant after all! Note that multiplying the coordinates of a matrix with those of its inverse (and summing according to the Einstein convention) gives the Kronecker delta, which is why we can swap out 

Coordinate-invariance shouldn’t surprise us too much, because the first two ways of writing the directional derivative made no mention of any coordinate system for
Now, recall that first-order differential operators on real functions of
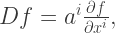
and so if we just interpret the values 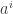
This correspondence with differential operators hints strongly at what quantities to use as our basis vectors – the individual derivative operators 

I say formal because we will not treat these basis vectors like ‘proper’ derivative symbols, as their ‘true’ meaning will only come into play in certain carefully-defined situations.
Let’s make the following abbreviations: 

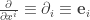
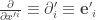
Linear functionals
A linear functional is a function 

Linear functionals are ‘vector-like’, but live in a space called 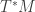

where the 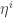
The expression 
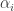
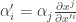

These linear functionals are also called covariant vectors, covectors, differential one-forms, or one-forms. Remember that both 
Total differential of a function
The following formula for the ‘total’ differential of a function should be familiar:

where 
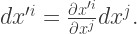
This is exactly how the basis for our covectors 
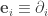
The full component-wise expression for the action of our covectors on our vectors is

The only trick here is 
Our expression for 

You may have spotted by now the value of the Einstein summation convention – as long as you keep your up-indices on vector components (and covector bases), and down-indices on covector components (and vector bases), any scalar you end up with will be coordinate-independent. This is a useful ‘type-check’ on any expression; if the indices don’t match, something must be wrong (or you’ve violated relativity by finding a preferred coordinate system).
I finish with three warnings:
- Covectors generated from functions (like
will not be the differential of any function at all.
- The components of vectors transform in the opposite way to the components of covectors. The basis vectors transform oppositely to the vector components, and to the basis covectors. This is confusing! Hence physicists like to pretend that basis vectors don’t exist, and only work with components. This is a convenient way to work for many computations, but you can end up getting confused when your basis vectors change from point-to-point (as they do on most non-trivial manifolds and coordinate systems):
Mathematicians never write any down coordinates, say they are working in a ‘coordinate-free’ way, and act all clever about it.
- There is one more way to write the directional derivative, which is
treating
. Unfortunately you also see people write the above as
which is very confusing, as it conflicts with our careful definitions of what the basis vectors and covectors mean – such is life.